LLM是什么
指的是包含超大规模参数(通常在十亿个以上)的神经网络模型,这些模型在自然语言处理领域得到了广泛应用。 大模型具有以下显著特征: 巨大的规模:大模型包含数十亿个参数,模型大小可以达到数百GB甚至更大。 这种巨大的模型规模使它们拥有强大的表达能力和学习能力。数据量大,参数量大,算力大。
兴起的主要原因
研究人员发现大模型在40B以上时会有涌现现象
- 数学基础
- 心理学基础
- 具体步骤与内容
- 遇到什么问题
- 解决方案
大模型的数学基础
线性代数
模型参数训练部分
矩阵乘法
加权求和
概率论
损失部分
准确率
贝叶斯估计
马尔可夫链
交叉熵损失
大模型的心理学基础
学习
深度学习—经典条件作用说
巴普洛夫的狗
把数据和标签提供给神经网络。神经网络对网络进行更新训练以使得神经网络中的结果和标签一致
强化学习—操作性条件作用说
斯金纳箱
把数据提供给神经网络。并在阶段中不断给予惩罚与奖励。促使网络向着有利的方向进行进化(了解不深)
记忆
大模型中的上下文信息
遗忘
识记过的信息不能回忆也不能再认,或者发生错误的回忆或再认。
推理
归纳推理
从特殊性归纳出普通性,类似于概念形成。(模型训练)
演绎推理
从普通性推理出特殊性,类似于问题解决。(模型预测)
智力
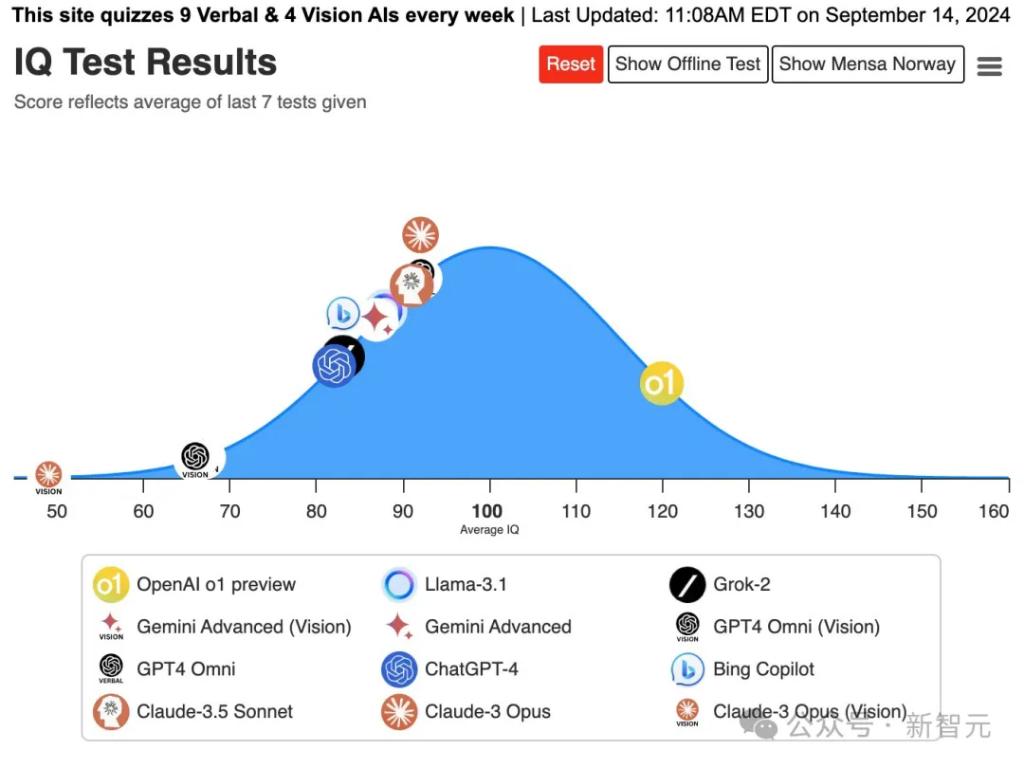
训练大模型需要哪些内容
模型结构
Transformer架构(注意力机制)
![]()
它的结构包括两部分:Encoder(编码器)和Decoder(解码器)。Encoder 与 Decoder 大致都包含以下层,每一层都有特定的功能,下面为 Encoder(编码器)各层的简单介绍:
- 输入嵌入层(Input Embedding Layer):将输入文本的词或标记转换为向量表示,以便模型能够理解它们。
- 位置编码(Positional Encoding):句子中词语相对位置的编码,保留词语的位置信息。
- 多头自注意力层(Multi-Head Self-Attention Layer):帮助模型捕捉输入序列中词与词之间的关系,使模型能够了解上下文信息。
- 前馈神经网络层(Feed-Forward Neural Network Layer):对多头自注意力的输出进行进一步的特征提取和变换,以增加模型的表示能力。
- 归一化层(Layer Normalization Layer):规范化每一层的输出,有助于训练过程的稳定性。
- 总的来说,Transformer 是一种强大的模型,它可以捕捉文本和序列数据中的长距离依赖关系,使其在翻译、对话、摘要生成等自然语言处理任务中表现出色。这个模型已经在各种应用中取得了显著的成功。
感兴趣的同学可以自行去网上搜索下 Transformer 的结构,深入了解。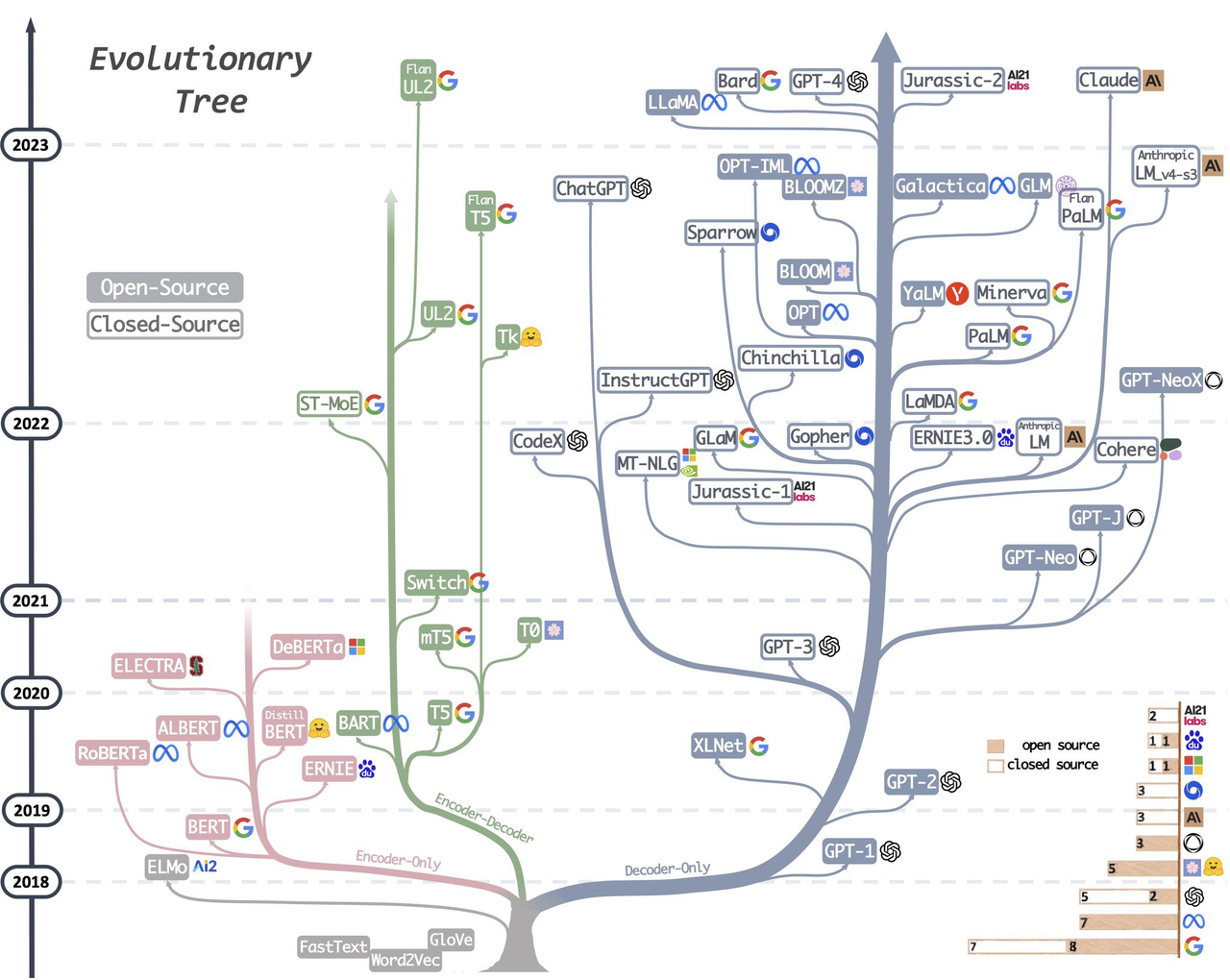
LLAMA的结构

我们来解读下上面 Llama 各层的结构与作用,首先从输入文本开始。会经过下面各层:
- Input Embedding:将 Input 文本转化为向量表,通过 nn.Embedding 实现。
- Llama Decoder Layer:Decoder 采用多层 Llama Decoder Layer。每一层包括自注意力(Llama Attention)和前馈网络(Llama MLP)。自注意力用于捕捉文本中的长程依赖关系。前馈网络进行非线性映射。
- Llama RMSNorm:一种规范化方式,用于正则化每层的输,起到预处理的作用。
- lm_head:一个线性层,将 Decoder 最后一层的输出映射到词典大小的维,以进行后续的语言模型 Logits 计算。
- Llama Attention:多头自注意力机制,用于建模文本中的依赖关系。将输入表示切分为多个头,然后在每个头内做点积注意力运算。
- Llama MLP:采用 Gated Linear Units 的多层前馈网络。进行非线性变换来捕捉复杂模式。
数据集(信息)GPT-3 dataset 为499B tokens
| Dataset | Quantity | Weight in Training Mix | Epochs Elapsed when Training for 300B Tokens |
|---|---|---|---|
| Common Crawl | 410B | 60% | 0.44 |
| WebText2 | 19B | 22% | 2.9 |
| Books1 | 12B | 8% | 1.9 |
| Books2 | 55B | 8% | 0.43 |
| Wikipedia | 3B | 3% | 3.4 |
| Dataset | Sampling prop. | Epochs | Disk size |
|---|---|---|---|
| Common Crawl | 67% | 1.10 | 3.3TB |
| C4 | 15% | 1.06 | 783GB |
| Github | 4.5% | 0.64 | 328GB |
| Wikipedia | 4.5% | 2.45 | 83GB |
| Books | 4.5% | 2.23 | 85GB |
| ArXiv | 2.5% | 1.06 | 92GB |
| StackExchange | 2.0% | 1.03 | 78GB |
Llama3 dataset为15T tokens
预训练
1B参数的大模型的训练需要64块A100显卡
GPT3的175B模型训练使用了1024块A100显卡共训练34天
Llama 3 405B 使用了16K H100 显卡
Epochs 一般为10个epoch以内

持续预训练
在原有数据基础上,继续进行预训练,数据量和预训练相同
对齐
在LLM对齐问题上,OpenAI提出的RLHF训练范式(人类反馈强化学习)最为人熟知,同时也是ChatGPT行之有效的对齐方案。
RLHF通常包含三个步骤:SFT, Reward Model, PPO, 该方案优点不需多说,缺点也很明显:训练流程繁琐、算法复杂、超参数多和计算量大,因此RLHF替代方案层出不穷。
大模型会遇到哪些问题
| 问题 | 灾难性遗忘 | 幻觉 |
|---|---|---|
| 定义 | 新任务学习时忘记旧任务 | 生成虚假或不准确的信息 |
| 表现 | 旧任务性能下降 | 生成的内容看似合理但不真实 |
| 发生场景 | 增量学习,持续学习 | 生成式模型如NLP中的文本生成 |
| 主要原因 | 参数更新过度适应新任务 | 生成概率最高的序列与实际情况不符 |
| 解决方法 | 知识蒸馏,正则化技术,增量学习,模型集成 | 增强数据多样性,使用外部知识库,严格的约束条件 |
Agent智能体
吴恩达提出:
- 反思(Reflection):Agent通过交互学习和反思来优化决策。
- 工具使用(Tool use):Agent 在这个模式下能调用多种工具来完成任务
- 规划(Planning):在规划模式中,Agent 需要规划出一系列行动步骤来达到目标。
- 多Agent协作(Multiagent collaboration):涉及多个Agent之间的协作。
Liliang Weng提出 - 规划:Agent需要具备规划(同时也包含决策)能力,以有效地执行复杂任务。这涉及子目标的分解(Subgoal decomposition)、连续的思考(即思维链,Chain of thoughts)、自我反思和批评(Self-critics),以及对过去行动的反思(Reflection)。
- 记忆: 包含了短期记忆和长期记忆两部分。短期记忆与上下文学习有关,属于提示工程的一部分,而长期记忆涉及信息的长时间保留和检索,通常是通过利用外部向量存储和快速检索。
- 工具:这包括了Agent可能调用的各种工具,如日历、计算器、代码解释器和搜索功能,以及其他可能的工具。由于大模型一旦完成预训练,其内部能力和知识边界基本固定下来,而且难以拓展,那么这些工具显得异常重要。它们扩展了Agent的能力,使其能够执行超出其核心功能的任务。
- 执行(或称行动):Agent基于规划和记忆来执行具体的行动。这可能包括与外部世界互动,或者通过工具的调用来完成一个动作(任务)。
CoT思维链
Chain-of-Thought(CoT)是一种改进的Prompt技术,目的在于提升大模型LLMs在复杂推理任务上的表现,对于复杂问题尤其是复杂的数学题大模型很难直接给出正确答案。如算术推理(arithmetic reasoning)、常识推理(commonsense reasoning)、符号推理(symbolic reasoning)。COT通过要求模型在输出最终答案之前,显式输出中间逐步的推理步骤这一方法来增强大模型的算数、常识和推理能力。简单,但有效。
ReAct框架(Reasoning-and-Acting)
这个框架整合了先前的CoT和Reflection方法,并引入了工具调用功能,进一步增强了模型的交互能力和应用范围,代表了在Agent认知框架发展中的一个新的里程碑。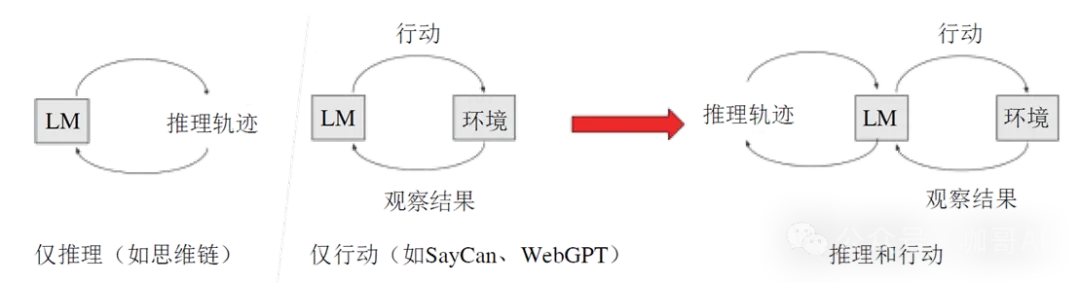
ReAct论文中指出,既要有推理,又要有行动
ReAct框架是推理和行动的整合,Reasoning and Acting, ReAct框架的核心思想在于在思考,观察和行动 反复循环,迭代,不断优化解决方案,知道问题最终解决位置,这就不仅使Agent能够进行复杂的内部推理,还能实时反应并调整其行为以适应不断变化的环境和需求。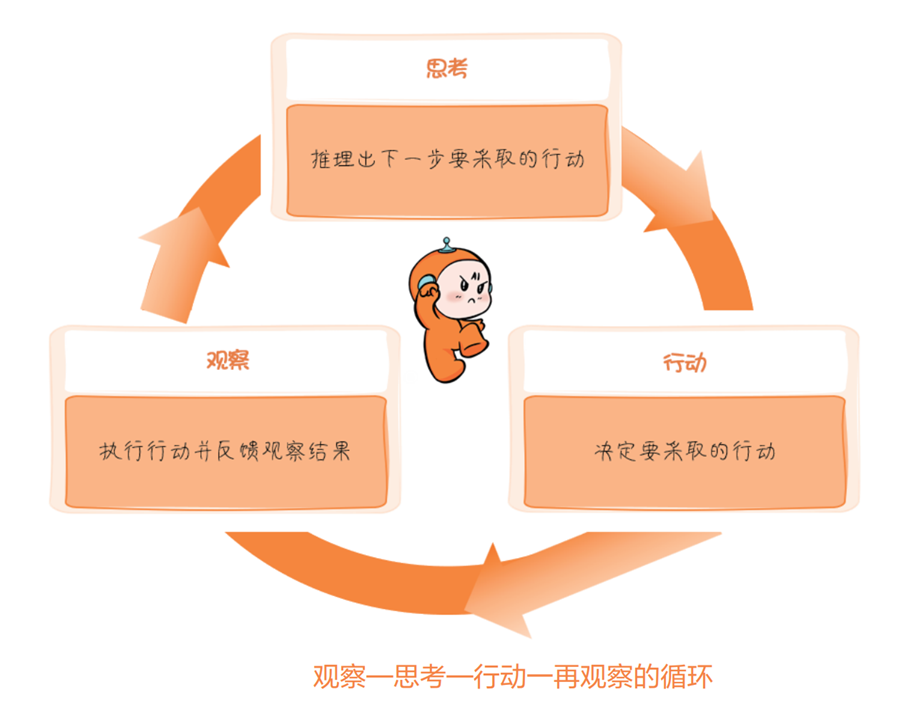
目前,ReAct框架已经被无缝集成至LangChain,开发者可以非常轻松地创建ReAct Agent来完成具体任务。
计划与执行框架(Plan-and-Execute)
Plan-and-Execute可以翻译为计划与执行架构。这种架构侧重于先规划一系列的行动,然后执行。它使LLM能够先综合考虑任务的多个方面,然后按计划行动。在复杂的项目管理或需要多步骤决策的场景中尤为有效,如自动化工作流程管理。
Plan-and-Solve论文中的示例
目前,LangChain的Experiment(实验包)中支持Plan-and-Execute框架,开发者可以尝试创建Plan-and-Execute Agent,对任务先计划,再具体执行。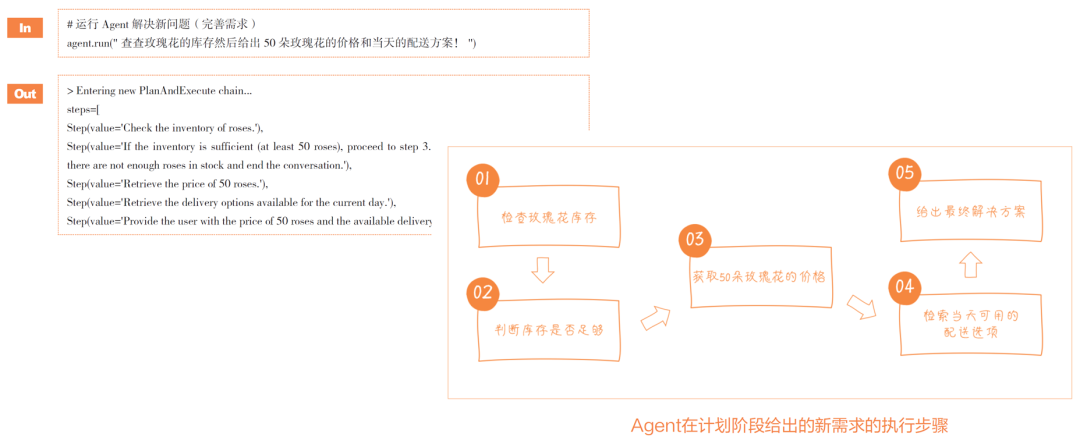
Plan-and-Solve的实现示例
多Agent协作(Multi-Agents Collaboration)
多Agent系统(Multi-Agent System)的确是一个新的研究热点。这类研究关注如何使多个Agent协同工作,实现复杂的任务和目标。这包括合作、竞争以及协商策略的研究。
这类多Agent协作框架的代表性作品是AutoGen和MetaGPT。
AutoGen框架中的Agent定制(Agent Customization)功能允许开发者对Agent进行定制,用以实现不同的功能。
MetaGPT的框架,它将标准操作程序(SOPs)与基于大模型的多智能体系统相结合,使用SOPs来编码提示,确保协调结构化和模块化输出。这种框架允许智能体在类似流水线方法的范式中扮演多样化的角色,通过结构化的智能体协作和强化领域特定专业知识来处理复杂任务,提高在协作软件工程任务中解决方案的连贯性和正确性。
MetaGPT的Demo中,构建了一个软件公司场景下的多Agent软件实体,它能够处理复杂的任务,模仿软件公司的不同角色。其核心理念是”代码等同于团队的标准操作程序(Code = SOP(Team))”,将标准操作程序具体化并应用于由大模型组成的团队。
软件公司组织角色图
这个软件公司的组织角色图突出了公司内的不同角色及其职责。
老板(Boss):为项目设定总体要求。
产品经理(Product Manager):负责编写和修订产品需求文档(PRD)。
架构师(Architect):编写和修订设计,审查产品需求文档和代码。
项目经理(Project Manager):编写任务,分配任务,并审查产品需求文档、设计和代码。
工程师(Engineer):编写、审查和调试代码。
质量保证(QA):编写和运行测试,以确保软件的质量。
你只要输入一行具体的软件开发需求。经过几轮协作,MetaGPT的假想软件工程团队就能够开发出真正可用的简单APP。
当然MetaGPT的功能不仅限于此,还可以用于其他场景构建应用程序。
各种认知框架的组合运用
上述认知框架当然是可以的组合的比如说,ReAct框架中,就一定应该配置Tool Calls,通过工具的调用+Tool Calls 才能够改变环境的状态,继续观察,才能够进一步的思考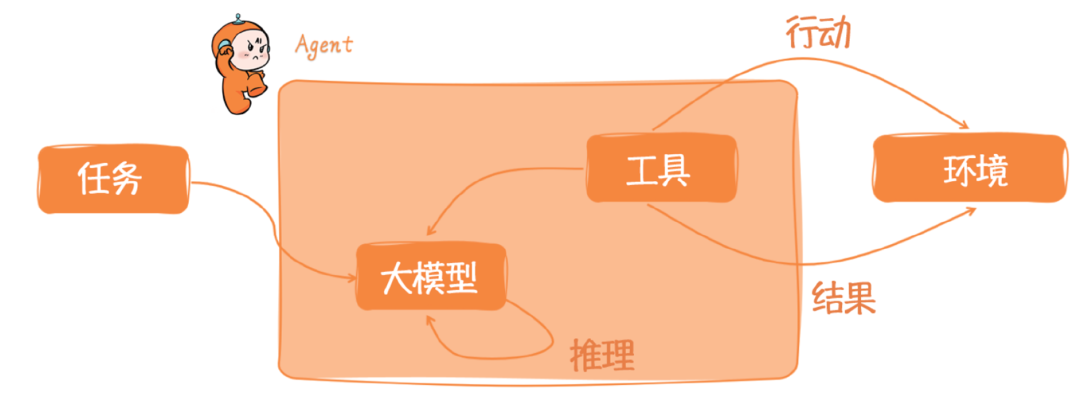
好吧,今天的干货分享就到这里。我试图用比较简短的篇幅,从理论到实践,全面系统地分析了Agent技术的发展现状,希望能够为你的Agent应用开发提供了参考和启发。未来,Agent技术的进一步发展将深刻影响人工智能在各领域的应用,推动人机协同迈上新台阶。
RAG增强检索
GraphRAG
成本较高,图谱构建困难,计算超级复杂,新增数据繁琐
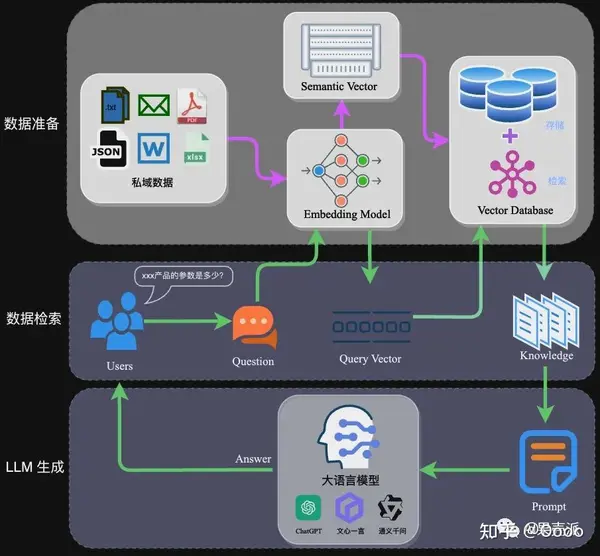
基于图的检索增强生成 (RAG) 方法,可以对私有或以前未见过的数据集进行问答。通过 LLM 构建知识图谱结合图机器学习,GraphRAG 极大增强 LLM 在处理私有数据时的性能,同时具备连点成线的跨大型数据集的复杂语义问题推理能力,其基于前置的知识图谱、社区分层和语义总结以及图机器学习技术可以大幅度提供此类场景的性能。
GraphRAG 方法可以归结为:利用大型语言模型 (LLMs) 从数据来源中提取知识图谱;将此图谱聚类成不同粒度级别的相关实体社区;对于 RAG 操作,遍历所有社区以创建“社区答案”,并进行缩减以创建最终答案。
GraphRAG的核心就是两个图,一个是文档图谱,一个是文档内部的实体关系图谱。
- 文档(Document)表示系统输入的文档。这些可以代表CSV中的单独行或单独的.txt文件;
- 文本单元(TextUnit)表示待分析的文本块。这些块的大小、重叠以及是否遵守任何数据边界可以进行配置。
- 实体(Entity)表示从文本单元中提取的实体。这些代表人、地点、事件或您提供的其他实体模型;
- 关系(Relationship)表示两个实体之间的关系;
- 协变量(Covariate)表示提取的声明信息,其中包含可能有时间限制的关于实体的陈述;
- 社区报告(Community Report)表示一旦生成实体,会对它们执行层次化的社区检测,并为这个层次结构中的每个社区生成报告;
- 节点(Node):包含已嵌入和聚类的实体和文档的渲染图视图的布局信息。
微调
全量微调
全量微调是指对整个预训练模型进行微调,包括所有的模型参数。在这种方法中,预训练模型的所有层和参数都会被更新和优化,以适应目标任务的需求。这种微调方法通常适用于任务和预训练模型之间存在较大差异的情况,或者任务需要模型具有高度灵活性和自适应能力的情况。Full Fine-tuning需要较大的计算资源和时间,但可以获得更好的性能。
增量微调
增量微调是指在微调过程中只更新模型的顶层或少数几层,而保持预训练模型的底层参数不变。这种方法的目的是在保留预训练模型的通用知识的同时,通过微调顶层来适应特定任务。Repurposing通常适用于目标任务与预训练模型之间有一定相似性的情况,或者任务数据集较小的情况。由于只更新少数层,Repurposing相对于Full Fine-tuning需要较少的计算资源和时间,但在某些情况下性能可能会有所降低。
微调方法详解
- Adapter调整
Adapter调整是在预训练模型的每个层或选定层之间插入小型神经网络模块(适配器)。这些适配器是可训练的,而原始模型的参数则保持不变。在微调过程中,只更新适配器的参数,从而实现对新任务的适应。 - 前缀调整
前缀调整是在输入序列前添加可训练、任务特定的前缀向量。这些前缀向量在训练过程中更新,以指导模型输出更适合特定任务的响应。前缀调整的优势在于不需要调整模型的所有权重,而是通过调整输入序列来影响模型输出。 - 低秩适应(LoRA)
LoRA方法通过引入两个低秩矩阵A和B来近似原始权重矩阵的更新。这两个低秩矩阵的维度远小于原始权重矩阵,从而减少了需要训练的参数数量。在微调过程中,只更新这两个低秩矩阵的参数,并将它们叠加到原始权重矩阵上,以实现模型行为的微调。
实施步骤 - 选择预训练模型
选择一个在大规模数据集上预训练好的模型,如BERT、GPT等。 - 准备新任务数据集
收集并处理与特定任务相关的数据集,包括训练集、验证集和测试集。 - 设置微调参数
根据任务特性和模型特点,设置合适的微调参数,如学习率、批处理大小、训练轮次等。 - 进行微调训练
在新任务数据集上对预训练模型进行进一步训练,通过调整模型权重和参数来优化模型在新任务上的性能。 - 评估与调优
使用验证集对微调后的模型进行评估,并根据评估结果调整模型结构和参数,直到达到满意的性能。 - 模型部署
将微调后的模型部署到实际的应用场景中,以实现模型的实用价值。
微调和RAG场景选择
场景维度
- 动态数据 RAG
- 模型能力定制 微调
- 幻觉 RAG>微调
- 可解释性 RAG
- 成本 RAG
- 依赖通用能力 RAG
- 延迟 微调
- 智能设备 微调
场景案例
- AI产品经理
- 处理动态数据 RAG
- 超级对话能力 RAG
- 业务能力 RAG
- AI程序员
- 很强规范阅读能力 微调
- 代码编写分析能力 微调